《算力时代》 哈希解读
《算力时代》| 哈希解读
你好,欢迎每天听本书,我是哈希。今天我要为你解读的这本书,叫《算力时代》。
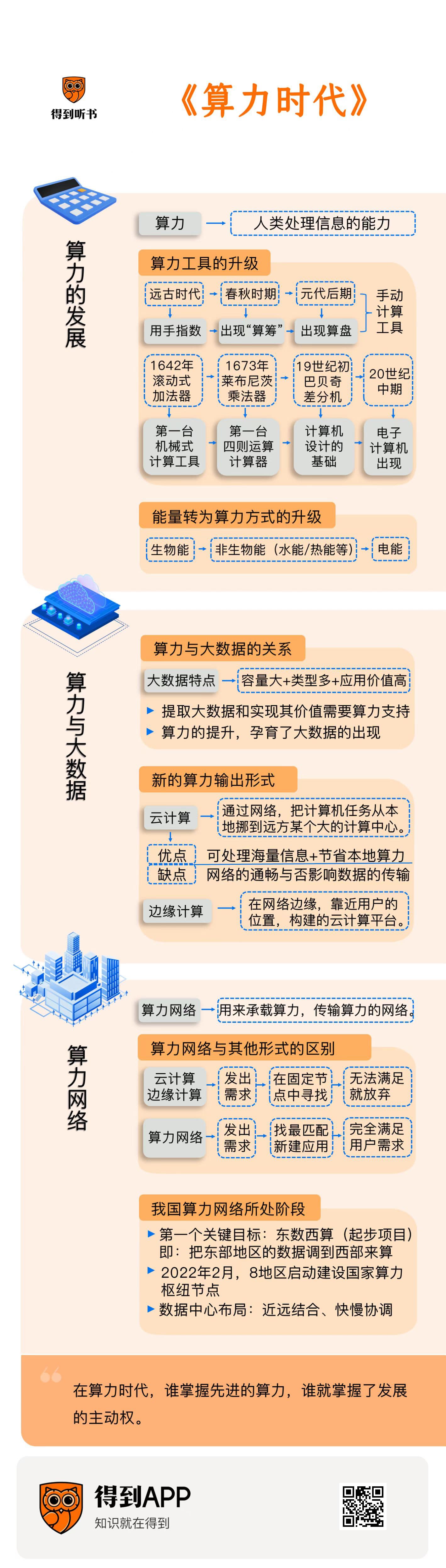
什么是算力呢?通俗来说,就是人类对信息的处理能力。从各种手机软件,到人们手上戴的智能手表、包里的笔记本电脑,再到有一个机房那么大的超级计算机,如果没有算力,它们就全都没法正常应用。而算力的高低,则决定了它们运行速度的快慢,以及它们能处理多复杂的问题。
举几个例子。比如,市面上常见的笔记本电脑,价格差异很大,这主要是因为它们的配置不同,高配置的笔记本有更高的算力,就可以同时运行更多软件,更快地处理各种数据表格,玩有更高配置要求的游戏。还有,拿手机来说,同样是玩网络游戏、看网络视频,手机的算力越高,体验就越流畅;不然,就容易出现滞后、卡顿的情况。另外,近些年人们常提到的人工智能,它们完成每一次人脸识别、每一次语音文字转换,都需要算力的支持。像这样的例子还有很多。可以说,如果没有算力,我们当下的生活将变得面目全非。
算力对社会的影响还远不止这些。这本书告诉我们,在当下,“算力时代”已经到来。这首先体现在,算力正在接替热力、电力,成为拉动经济向前发展的新引擎;另外,算力已经成为影响国家综合实力和国际话语权的关键要素,成为一个国家的核心竞争力。在未来,谁掌握的算力更强大,谁就掌握了发展的主动权。这些,在后面的讲述中,我们还会给出具体的数据作为佐证。
这本书由中国移动研究院负责内容研发,有三位主要作者,分别是中国移动通信集团公司技术部总经理王晓云、中国移动研究院副院长段晓东,还有中国移动研究院网络与IT技术研究所所长张昊。在书里,三位作者梳理了算力的演化历程,还探讨了算力的应用场景、算力的未来发展、算力网络的构建等话题。
今天,我会分三部分,为你讲解书里的重点内容。首先第一部分,我们来梳理一遍从古至今,算力的发展历程;第二部分,我们重点来说一说,在当下,数据与算力之间是什么关系;第三部分,我们讲一讲咱们国家算力网络的构建,并重点讲一个2022年正式启动的国家级重要工程——“东数西算”。
好,首先我们进入第一部分,说一说算力的发展历程。
算力这个词,听起来是个新词。但事实上,它在很早以前就存在了。我们在开头讲了,算力,就是人类处理信息的能力;所以,算力的发展历程,就是人类处理信息能力的发展历程。
这个历程是从什么时候开始的呢?从远古时期,我们用两只手,10个手指头数数的时候就开始了,这也是为什么,现在的人们,依然习惯用十进制计数法。到了中国的春秋时期,人们开始用长度、粗细都相近的小棍子来记数。这些小棍子能通过横竖不同的摆放方法,来表示从1到9这9个数字,这就是“算筹”,筹码的筹,也是人类社会最早出现的“算力”。
算筹可以帮人们实现基本的记数,但是对于数字的加减乘除这些计算来说,靠摆放小棍子就很麻烦了。所以后来,到了元代后期,一种新的计算工具——算盘出现了,它代替了算筹,成为历史上公认的、最早得到大规模使用的计算工具,还先后流传到日本、朝鲜还有众多东南亚国家,后来又传入西方。钱学森曾经说:“算盘的发明,并不比中国古代的四大发明逊色,在某种程度上来说,算盘对世界的贡献要远大于四大发明。”
上面介绍的算筹、算盘都是手动式的计算工具。借助它们,我们可以完成简单的数字加减乘除,但是遇到计算量较大的时候,就力不从心了。后来,随着机械工具逐渐渗透到了人类的日常生活和劳作中,在计算领域,也出现了机械式的计算工具。相比于手动式的计算工具,机械式的计算工具,能应付更大的计算量。
比如,1642年,法国数学家帕斯卡发明了一种滚轮式的加法器。这种加法器的外形是一个长方体盒子,盒子里面,从右到左分布着5个定位齿轮,分别代表个、十、百、千、万。使用的时候,人们用钥匙旋紧发条,来转动每个齿轮,顺时针拨动齿轮是做加法,逆时针拨动是做减法。这是人类历史上第一台机械式计算工具,对后来的计算工具的发明产生了很大影响。
又过了大约30年,到1673年的时候,德国数学家莱布尼茨在帕斯卡加法器的基础上进行了改进,让它能进一步实现乘法和除法的计算。这台机器被人们称为“莱布尼茨乘法器”,是历史上第一台能进行四则运算的机械式计算器。
后来,在19世纪初,英国数学家查尔斯·巴贝奇又发明了一种更加多功能的计算器,叫“巴贝奇差分机”。那这台计算器比之前的厉害在哪呢?厉害在,它不仅能计算,还能储存数据。具体技术细节我们不用去了解,大致就是,它里面有齿轮式的储存库,每个齿轮可以储存10个数,齿轮组成的阵列一共可以储存1000个50位的数。后来,在差分机的基础上,巴贝奇又发明了一种分析机。这种分析机由存储装置、运算装置和控制装置三部分组成,这种设计思路为现代计算机的设计思想奠定了基础,时至今日,我们使用的计算机都遵循着这样的基本设计理念。
时间从巴贝奇生活的19世纪,来到20世纪中期。这个阶段,电子计算机出现了。这就使得人们的计算工具发生了质的改变,从机械工具变成了电子工具,从每一步都要人工操作,变成了下达指令、自动计算。电子计算机的计算能力主要取决于它内部的芯片。从20世纪中期第一台电子计算机出现,到今天,随着芯片性能的不断提升,计算机的体积越来越小,运算速度越来越快。从一开始占地面积一百多平方米、有一栋房子那么大,到现在只有一本书那么大、可以轻松地装进皮包;从一开始每秒可以运行几百至几千次运算,到现在可达到每秒上千万次、万亿次甚至更高。
除了电子计算机以外,在当下,我们还能见到很多其他以芯片为核心的算力工具。比如,智能手机,它是把数据计算、图形计算、信号处理等多种功能都集成在一颗小小的芯片上。还有智能手表、智能耳机、智能跑鞋、智能家居,等等,它们之所以能接收我们产生的行为数据,是因为有传感器,而要分析这些数据,并且给出相应的反馈,就得靠它们内部的集成处理芯片了。
到这里,总体回顾一下算力的发展历程,从中,我们能发现两条相互交织的发展脉络。第一条脉络是,算力工具本身的升级,从最初的算筹、算盘,到各种机械装置,到今天的电脑、手机,我们处理信息的手段在不断进化。第二条脉络是,人类把能量转化为算力的方式也在不断升级。你看,最开始,人类对信息的处理是纯手工的,是把人体的生物能转化为信息处理能力;后来,有了帕斯卡加法器、莱布尼茨乘法器、巴贝奇差分机这些机械装置,人们除了可以手动操作这些机械以外,还可以用水能、热能等非人体生物能的能量来驱动它们;后来,随着电磁学的发展,以电能驱动的电子计算机终于出现;而在当下,随着芯片性能的不断升级,人类也能更高效地利用电能驱动算力。
历史学家大卫·克里斯蒂安曾经说过:人类一直在追求能量和信息效用的最大化。可以说,人类的科技发展史,就是不断提升对能量的使用能力,对信息的处理能力的历史。而这些,在我们梳理的算力发展史中,都非常明显地有所体现。可以说,算力发展史,是人类科技发展史中,一条隐藏的重要主线。
刚才,我们整体地捋了一遍算力的发展史。中国移动董事长杨杰曾经说:“算力是继热力、电力之后,新的关键生产力。”的确,如果说,第一次工业革命带人们进入了热力时代,第二次工业革命带人们进入了电力时代,那么由计算机推动的第三次工业革命,则带人们进入了一个算力时代。数据、算力和算法构成了这个时代最基本的生产基石。用阿里云中国区副总裁陈斌的话来说就是,“数据是新的生产资料,算力是新的生产力,算法是新的生产关系。”
在这本《算力时代》里,作者并没有专门对算法做讨论。不过,得到听书之前为你解读过的《算法之美》《从祖先到算法》《算法的陷阱》等很多本书,都是专门讲算法的。感兴趣的话,你可以直接在听书文稿里点开这几本听书的链接,去做拓展了解。今天,我们重点说一说书里面讲到的,数据跟算力的关系,尤其是,在当下,大数据跟算力之间,到底是什么关系。
平时,我们总是先讲到大数据,然后再提到算力的发展。这里面默认的逻辑是,因为大数据发展起来了,所以我们需要更高的算力去处理它。但是,从这本书来看,它俩的产生顺序恰恰是相反的——是因为有了算力的提高,所以才有大数据的出现。
为什么呢?你看,咱们都知道,大数据最突出的特点就是容量大、类型多。在当下,我们很多日常行为都在不断地生成数据。比如一张火车票,在以前,它只是通行证,但现在,它是一条出行数据,会积累到你的个人数据里。再比如去吃饭、去购物,以前用现金支付,留不下任何痕迹,但现在通过网络支付,你的这些交易行为也都变成了一条条行为数据。还有,如果你佩戴了智能手表,或者家里安装了各种智能家居设备,那它们也在不断地收集你的身体数据和行动数据。你会发现,我们做的事情本质上并没有变,像坐车、吃饭、交易、运动等等这些活动,都是我们一直就在做的事情,只不过,近些年人们才有能力把它们转化为可以用的数据。这件事本身,就需要算力的支持。因为如果没有足够的算力,我们就没法对这些数据进行收集、描述、归类,就没办法把这些数据从现实世界里,妥帖地录入到数据库里。
再有,咱们刚才仅仅只说了大数据前两个特征:容量大、类型多。但是,根据咱们国家对大数据的官方定义,大数据不仅是容量大、类型多,还要应用价值高。数据的应用价值怎么体现呢?就是要经历一个从数据,到信息,再到知识的过程。比如在一家餐馆里,我们收集到了顾客的点单时间、点的菜品还有付款金额,这就是数据;通过数据能了解到顾客们对菜品的偏好,还有一天中不同时段的客流量变化,等等,这就是信息;再根据这些信息,总结出规律,制定相应的经营策略,这就是知识。数据、信息和知识是层级递进的关系。光有数据是没有用的,你必须要把它做一个系统性的整理,变成信息,甚至再把信息做更加简洁抽象的加工,变成知识,才算是实现了数据的应用价值。而不管是对数据的整理还是加工,靠的都是计算机的计算能力,也就是,都需要算力作为支持。
所以,简单来说,不管是要把大数据从现实世界里提取出来,还是要实现大数据的应用价值,都需要算力的支持。所以,不是先有了大数据,才需要算力的提升;而是算力的提升,孕育了大数据的出现。
刚才我们讲到了手机、电脑,还有各种智能设备,它们的算力主要依靠的是内部的处理芯片。而在大数据时代,光靠这些内部处理芯片来计算已经不够了,还需要互联网云端来为人们提供计算。
这里,就要讲到一个近几年很火的词了——“云计算”。没错,这是在大数据时代,一种重要的算力输出形式。你之前可能也了解过它。通俗来说,云计算就是,通过网络,把计算任务从本地挪到远方的某个大的计算中心——有可能是在另一个城市,甚至另一个国家;在远方的计算中心完成计算之后,再把计算结果返回本地。这样,就节省了本地的算力,不用花大功夫在本地部署算力很强的设备了。
有人这样比喻云计算,说它就像一颗独立于人类之外的超级大脑,我们人类产生的所有信息,都可以立刻上传给这颗超级大脑,让它帮我们运算,得出结果。本来,我们人类的智能是有限的,但现在借助这颗超级大脑,我们就相当于拥有了处理海量信息的无限能力。
当然,这颗超级大脑,也是有实体的。它的实体,就是在远方的计算中心里,那一台台依靠电力维持的服务器。如果想要拥有更大的算力,就要制造更多的服务器。比如,谷歌云计算拥有的服务器,早已超过100万台,亚马逊、IBM、微软等公司也都拥有超过几十万台的服务器。
但是,云计算也不是没有缺点。比如说,一个云计算中心建立在A城市,在很多其他的、离A城市很远的城市里,每天都有无数人的数据传到A城市的计算中心,计算完再传回去。那么这个时候的传输网络,就像是挤了无数辆车的公路一样,容易发生堵塞,或者产生事故。这反映在我们的体验上,就是一些操作指令有延迟、加载不出来,或者干脆界面崩溃、出现错误,等等。
而有一种新的计算方式,能在一定程度上缓解这个问题。它叫边缘计算。书里把边缘计算称为云计算的“小弟”。因为它是跟云计算一脉相承,基因相似的。边缘计算平台,本质上就是在网络边缘,也就是在靠近用户的位置上,构建的云计算平台。就类似于,在我们刚才说的那条挤了无数辆车的公路的边缘,又支出一些分叉的道路,疏通了车流。关于边缘计算的技术细节,我们在听书中就不再展开了,感兴趣的朋友,可以在原书的第七章中看到更多细节。
好,刚才我们主要讲了,算力跟数据的关系,还有在大数据时代,两种重要的算力输出形式——云计算和边缘计算。刚才我们提到,在数字化的经济社会,数据已经成为新的生产资料,而算力则是新的生产力。说算力是新的生产力,并不是一句口号,而是有证据支持的。根据中国信息通信研究院的测算,在2020年,我国算力产业规模达2万亿元,直接和间接带动的经济产出,加在一起是8万亿元;所以平均来看,在算力产业上每投入1元,将带动3—4元GDP经济增长;并且,算力产业规模每增长1%,能撬动GDP增长0.2%。
算力之所以能对经济产生这么大的拉动作用,这背后还有一个重要角色的支持,那就是算力网络。这就是我们接下来这部分要讲的重点。
算力网络,顾名思义,就是用来承载算力,传输算力的网络。就像电力的传输要靠电网,水力的传输要靠水网一样,算力的传输也要依赖算力网络。目前我们国家对于算力网络的建设目标,就是想让算力网络成为继水网、电网之后的国家新型基础设施。让算力能够真正地流动起来,像电力和自来水一样能实现随用随取。
说到这里,你可能会产生一个疑问:刚才我们提到的云计算、边缘计算,不也是在努力满足用户随时随地的算力需求吗?那云计算、边缘计算跟算力网络的区别在哪呢?
对于这个问题,书里有一个形象的比喻。我们可以想象一家品牌连锁炸鸡店,在每个城市都有很多家分店。如果是采用云计算、边缘计算的方式,那么这个炸鸡店的所有分店的个数和位置都是提前固定的。当一个人需要算力的时候,或者说饿了、想吃炸鸡的时候,他只能去一家离自己最近的炸鸡分店去吃饭,如果这家分店正好客满,那么他就得再去找别的店;如果所有分店都客满,那就只能等着,或者放弃这个需求。
而在有了算力网络后,用户只需要打开某款软件,输入关键字“炸鸡”,就可搜索出此刻最适合去的炸鸡店;软件还能自动规划出行车路线,指引用户前往。而且,算力网络除了可以指引用户去已有的炸鸡店外,还可以在离用户最近的地方快速建一个炸鸡店,不会让用户的需求落空。
我再把这段话翻译一下。就是在有了算力网络后,你打开算力网络平台,输入自己的算力需求,就可以找到此刻最能满足你需求的算力应用,平台还会帮你打通你跟算力应用所在的算力节点之间的网络连接。而且,算力网络还可以根据客户当前所在位置,在离用户最近的地方快速直接拉起一个算力应用,并指引客户前往。总结来说就是,算力网络比云计算、边缘计算的灵活性更强。在算力网络搭建完全之后,算力就能真正地流动起来,成为我们能够随取随用的一种资源。
那么,我们国家的算力网络建设现在进行到什么阶段了呢?书里告诉我们,在当下,我国算力网络建设的第一个关键目标,是实现“东数西算”。
这里面的“数”,指的是数据;“算”就是我们今天一直在说的算力,也就是对数据的处理能力。“东数西算”,就是把我国东部地区的数据,调到西部地区来计算。它和著名的南水北调、西电东送、西气东输是同一个系列的工程,分别解决水、电、气和算力的全国统一调配问题。
为什么东部地区的数据,不在东部地区计算,而要调到西部地区呢?这是因为,一个用来储存和处理数据的数据中心,不仅要占用很多的土地资源,而且能耗也很高,对电力和水资源的需求很大。东部地区的情况是,土地和能源都比较紧缺,但是要计算的数据很多;西部地区的情况是,要计算的数据相对少一些,但是土地和能源比较充足。实行“东数西算”,就能让东西部这种对算力的需求和供给失衡的情况得到解决,提升资源的使用效率。
所以,在2022年2月,国家发改委联合多个部门印发通知,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏等8个地区启动建设国家算力枢纽节点。这标志着“东数西算”工程的正式启动。
注意,在这8个算力枢纽节点里,有三个是位于京津冀、长三角、珠三角这些数字经济发达的东部地区的。这些算力枢纽里的数据中心,主要负责一些必须快速响应的数据处理业务,比如工业互联网、金融证券、灾害预警、远程医疗,等等。这些就可以在东部地区的数据中心就近消化。还有一些不需要快速响应的数据处理业务,比如后台加工、离线分析、存储备份,等等,就可以率先向西部的算力枢纽转移,由那里的数据中心来承接。用这种近远结合、快慢协调的数据中心布局,来实现算力资源的灵活调配。
当然,“东数西算”还只是我国算力网络建设的起步项目,是宏伟征途的第一阶段。接下来,相信我们的步伐会越迈越快,逐步地让算力网络覆盖神州大地的每个角落,让算力像电力和自来水一样,能实现随用随取。
好,以上,就是《算力时代》这本书里,我想跟你分享的重点内容。总结一下:
算力的大小,代表着人类对信息处理能力的强弱。回顾算力的发展历程,我们能看到,从原始社会的手动式计算,到后来的机械式计算,再到现代的电子计算、数字计算,算力集中代表了人类智慧的发展水平。
如果说,第一次工业革命带人们进入了热力时代,第二次工业革命带人们进入了电力时代,那么由计算机推动的第三次工业革命,则带人们进入了一个算力时代。数据、算力和算法构成了这个时代最基本的生产基石。具体来说就是,数据是新的生产资料,算力是新的生产力,算法是新的生产关系。
在当下,人类要处理的数据体量迎来了爆炸式的增长,“大数据”的概念频繁出现。平时,我们总是先讲到大数据,然后再提到算力的发展。这里面默认的逻辑是,因为大数据发展起来了,所以我们需要更高的算力去处理它。但是,这本书提醒我们:不管是要把大数据从现实世界里提取出来,还是要实现大数据的应用价值,都需要算力的支持;所以,如果没有算力的提高,根本就不会有大数据的出现。
后面,我们还讲到了两种在大数据时代常见的算力输出方式——云计算和边缘计算。也讲到了它们跟算力网络的区别。总结来说就是,算力网络比云计算、边缘计算的灵活性更强。在算力网络搭建完全之后,算力就能真正地流动起来,成为我们能够随取随用的一种资源。而在当下,我国算力网络建设的第一个关键目标,是实现“东数西算”。也就是把我国东部地区的数据,调到西部地区来计算。它和著名的南水北调、西电东送、西气东输是同一个系列的工程,分别解决水、电、气和算力的全国统一调配问题。
最后,我们从中国放眼到全球。中国信息通信研究院在2021年9月份发布了一份《中国算力发展指数白皮书》,在里面,我们能看到,各国的算力规模和GDP水平呈现出了很强的相关性。在2020年,算力规模排名前三的国家,和GDP排名前三的国家是一致的。其中,美国占全球总算力的36%,中国占31%,日本占6%,欧洲作为一个整体,占11%。
目前,全球算力处于加速增长的阶段。2016年—2020年,全球算力规模平均每年增长30%。而2020年—2025年,预计全球算力规模增速会再上一个台阶,达到每年增长50%。世界主要国家都在投入巨资,加快算力布局,算力已经成为大国战略竞争的新焦点。可以说,在算力时代,谁掌握先进的算力,谁就掌握了发展的主动权。而了解算力,则是对所有想要参与这个时代的人,一个最基本的要求。
好,今天这本书,我们就聊到这里。你可以点击音频下方的“文稿”,查收这本听书的全文还有脑图。原书电子版已经为你附在最后,欢迎你进行拓展阅读。你还可以点击右上角的“分享”按钮,把这本书免费分享给你的朋友。
恭喜你,又听完了一本书。
划重点
-
由计算机推动的第三次工业革命,带人们进入了一个算力时代。数据、算力和算法构成了这个时代最基本的生产基石。具体来说就是,数据是新的生产资料,算力是新的生产力,算法是新的生产关系。
-
在当下,我国算力网络建设的第一个关键目标,是实现“东数西算”。也就是把我国东部地区的数据,调到西部地区来计算。
-
在算力时代,谁掌握先进的算力,谁就掌握了发展的主动权。而了解算力,则是对所有想要参与这个时代的人,一个最基本的要求。